

As AI adoption accelerates across industries, organizations face a critical decision: how to optimize large language models (LLMs) for their specific needs. Two dominant approaches have emerged: Retrieval-Augmented Generation (RAG) and fine-tuning, each offering distinct advantages for different use cases.
This comprehensive guide explores both methods, helping you choose the optimal approach for your AI implementation strategy.
What is RAG (Retrieval-Augmented Generation)?
RAG plugs an LLM into stores of current, private data that would otherwise be inaccessible to it. Instead of modifying the model itself, RAG enhances responses by retrieving relevant information from external databases in real-time.
To understand how RAG works in practice, let’s examine the step-by-step process that occurs every time a user submits a query to a RAG-powered system:
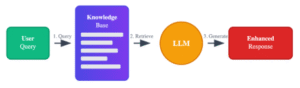
RAG workflow showing how user queries trigger real-time information retrieval from external knowledge bases before generating enhanced responses.
RAG excels at providing up-to-date information seamlessly. If there’s new data like today’s news or a new company policy, a RAG-based solution can immediately use it to answer questions by retrieving it. This makes RAG particularly valuable for applications requiring current information like customer support, news analysis, or dynamic knowledge bases.
What is Fine-Tuning?
Fine-tuning is the process of retraining a pretrained model on a smaller, more focused set of training data to give it domain-specific knowledge. Unlike RAG, fine-tuning modifies the model’s internal parameters to specialize its behavior for specific tasks or domains.
The fine-tuning process transforms a general-purpose model into a domain expert through supervised learning. Here’s how this transformation occurs:

Fine-tuning process demonstrating how a base model is retrained with domain-specific data to create a specialized model with enhanced capabilities.
Fine-tuning generally yields very high accuracy on domain-specific tasks because the model has learned the domain inside-out from training data. It produces outputs well-tailored to context, using correct terminology and providing solutions aligned with training examples.
Key Differences: RAG vs Fine-Tuning Comparison
While both methods aim to enhance LLM performance, they operate on fundamentally different principles. Understanding these distinctions is essential for selecting the right approach for your specific use case. The following visual comparison breaks down the critical factors that differentiate these two methodologies:
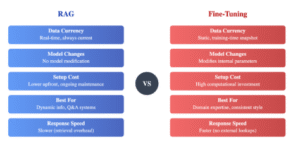
Comprehensive comparison highlighting the fundamental differences between RAG and fine-tuning approaches across key implementation factors.
Understanding these fundamental differences is crucial for making informed decisions about which approach suits your specific needs. The choice between RAG and fine-tuning isn’t just technical—it impacts your project timeline, budget, maintenance requirements, and long-term scalability. Let’s explore the specific scenarios where each method excels.
When to Choose RAG
RAG is ideal for applications requiring real-time access to dynamic information, while fine-tuning is preferred for scenarios demanding precise, task-specific outputs. Choose RAG when you need:
- Dynamic Knowledge Requirements: With RAG, the model’s knowledge can be as fresh as the latest entries in the database, updated to the minute if needed. Perfect for customer support systems, news aggregation, or any application requiring current information.
- Cost-Effective Implementation: RAG tends to be more cost efficient than fine-tuning, especially for organizations wanting to enhance model capabilities without massive computational investments.
- Multi-Domain Applications: RAG can handle multiple domains by switching data sources while using the same model, a more practical solution many companies have discovered.
While RAG offers flexibility and real-time capabilities, there are scenarios where fine-tuning’s deep specialization becomes more valuable than dynamic information access.
When to Choose Fine-Tuning
A fine-tuned legal model will likely outperform both non-fine-tuned models and RAG approaches on legal question-answering benchmarks. Select fine-tuning for:
- Domain Specialization: When you need deep expertise in specific fields like healthcare, legal, or technical documentation where precision and specialized terminology are crucial.
- Consistent Style and Tone: A business could fine-tune an LLM to build a chatbot that reflects its brand’s tone for a better conversational style with customers.
- Performance-Critical Applications: With fine-tuned models, everything is handled within the pre-trained model, meaning responses are generated instantly without external lookups.
Rather than viewing RAG and fine-tuning as competing approaches, forward-thinking organizations are discovering the power of combining both methodologies to create more robust AI solutions.
Hybrid Approach: The Future of AI Optimization
A hybrid approach combining both can offer enhanced contextual understanding and improved response accuracy. Modern AI implementations increasingly use both methods together:
- Fine-tune for domain expertise while using RAG for current information
- Company knowledge embedded through fine-tuning with real-time data via RAG
- Specialized tasks handled by fine-tuned models with factual grounding from RAG systems
Successfully implementing either approach requires following established best practices that have emerged from real-world deployments across various industries.
Implementation Best Practices 2025
Successfully deploying RAG or fine-tuning systems requires more than just understanding the theory—it demands practical knowledge gained from enterprise implementations. Based on the latest industry insights and technological advances in 2025, here are the proven strategies that ensure optimal performance for each approach.
- For RAG Systems:
-
- Maintain high-quality, regularly updated knowledge bases
- Optimize retrieval mechanisms for speed and relevance
- Leverage rich, up-to-date sources and ensure that the external knowledge base is comprehensive and regularly updated
- For Fine-Tuning:
-
- With LoRa (Low-Rank Adaptation), a popular method for fine-tuning, the process is made more efficient and cost-effective
- Start with high-quality, domain-specific datasets
- Monitor for model drift and plan regular retraining cycles
With these best practices in mind, the ultimate decision comes down to evaluating your specific requirements against each method’s strengths and limitations.
Making the Right Choice
Your decision between RAG and fine-tuning should consider:
- Information volatility – Choose RAG for rapidly changing data
- Resource constraints – RAG typically requires lower upfront investment
- Performance requirements – Fine-tuning offers faster response times
- Domain specificity – Fine-tuning excels in specialized fields
- Maintenance capabilities – Consider long-term update requirements
Both RAG and fine-tuning represent powerful approaches to AI model enhancement. Sometimes, a mix of both approaches can be the best way to balance staying current with accuracy. The optimal choice depends on your specific use case, available resources, and performance requirements.
As AI technology continues evolving in 2025, successful organizations will leverage the strengths of both approaches, creating robust AI systems that combine real-time knowledge access with domain-specific expertise.